



k-means法(k-means clustering)は、データをk個のクラスター(グループ)に分割するための教師なし学習アルゴリズムです。
データの分類やパターン認識、異常検知などに広く使われます。
Contents
k-means法の基本的な流れ
k-means法の基本的な流れは、以下のとおりです。
- 初期化
データからランダムにk個のクラスタ中心(セントロイド)を選ぶ。 - クラスター割り当て
各データポイントを、最も近いセントロイドに割り当てる。 - セントロイドの更新
各クラスターの平均を計算し、新しいセントロイドを求める。 - 収束判定
セントロイドの位置が変わらなくなるまで②と③を繰り返す。
この手法はシンプルながら、クラスター分析の基礎として非常に有用です。
Pythonによるk-meansの実装
Pythonでは、scikit-learnライブラリを使用すると簡単にk-means法を実装できます。
また、numpyやmatplotlibを使ってデータの可視化も行います。
必要なライブラリのインストール
まず、必要なライブラリをインストールします。
pip install numpy matplotlib scikit-learnサンプルデータの作成
make_blobs関数を使って、クラスタリング向けのサンプルデータを作成します。
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_blobs
from sklearn.cluster import KMeans
# サンプルデータの作成
X, y = make_blobs(n_samples=300, centers=3, cluster_std=0.60, random_state=0)
# 散布図の描画
plt.scatter(X[:, 0], X[:, 1], s=50)
plt.title("Generated Data")
plt.show()k-meansクラスタリングの実装
scikit-learnのKMeansを使ってクラスタリングを実装します。
# k-meansの実行
kmeans = KMeans(n_clusters=3, random_state=0)
kmeans.fit(X)
# クラスターの中心を取得
centers = kmeans.cluster_centers_
labels = kmeans.labels_
# 結果のプロット
plt.scatter(X[:, 0], X[:, 1], c=labels, cmap='viridis', s=50)
plt.scatter(centers[:, 0], centers[:, 1], c='red', marker='x', s=200, label='Centroids')
plt.title("K-means Clustering Result")
plt.legend()
plt.show()実行結果は以下のとおりで、3つのクラスターができています。
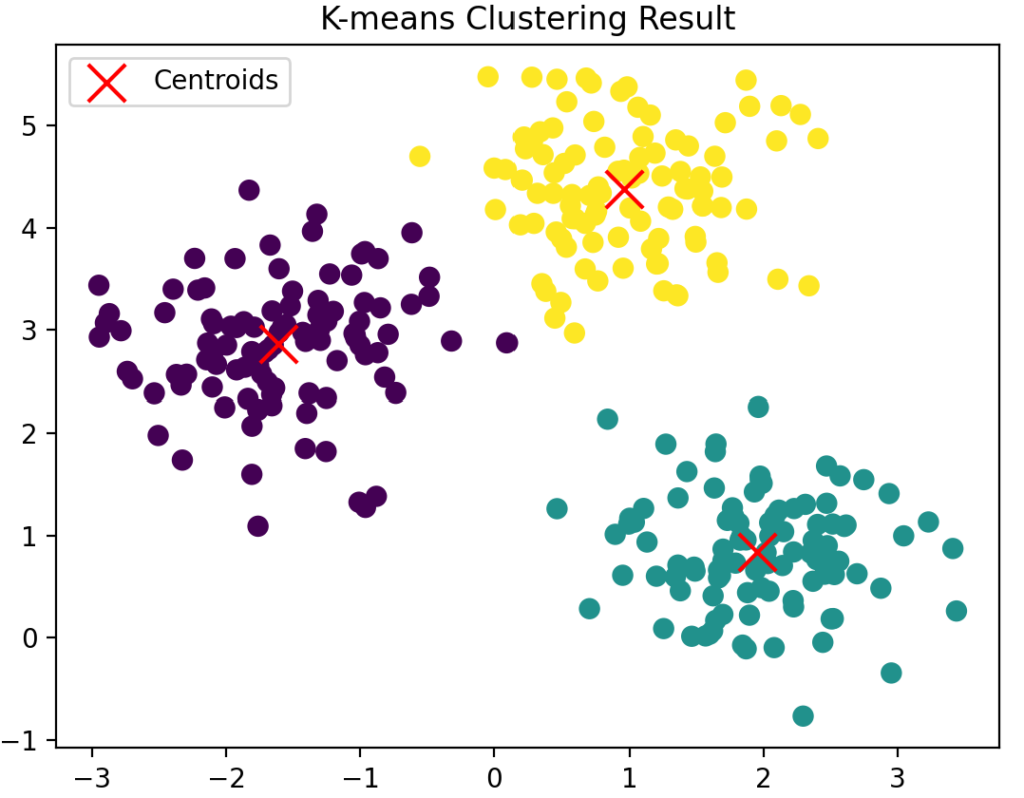
Elbow法による適切なkの選び方
k-meansでは、クラスター数(k)を事前に決める必要があります。
適切なkを選ぶ方法の一つとして、Elbow法が挙げられます。
inertia = []
k_values = range(1, 10)
for k in k_values:
kmeans = KMeans(n_clusters=k, random_state=0)
kmeans.fit(X)
inertia.append(kmeans.inertia_)
# エルボー法のプロット
plt.plot(k_values, inertia, marker='o')
plt.xlabel("Number of clusters (k)")
plt.ylabel("Inertia")
plt.title("Elbow Method for Optimal k")
plt.show()実行結果は以下のとおりです。
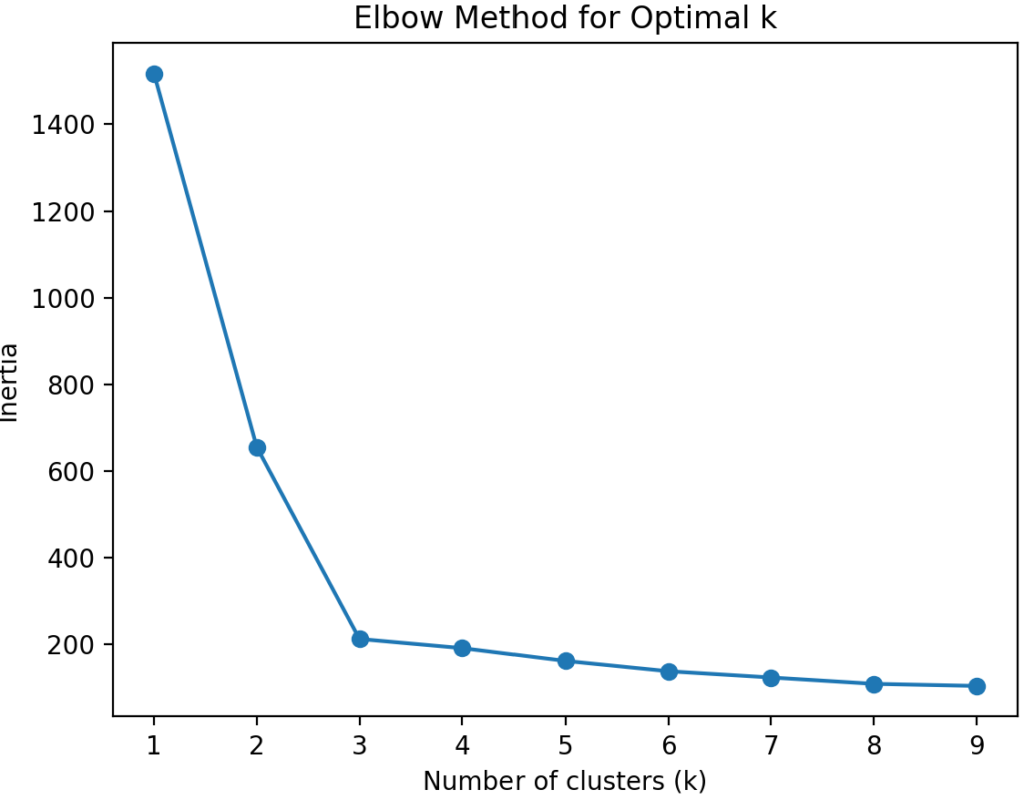
エルボー法では、グラフの「ひじ」(曲がるポイント)を最適なkと判断します。
上図から、3が適切なkと判断できます。
まとめ
k-means法は、データをk個のクラスターに分割する基本的なクラスタリング手法です。
本記事では、以下の内容をまとめました。
- k-means法の概要
- Pythonを使った実装方法
- Elbow法を用いた適切なkの選び方
実際のデータ分析においては、k-meansのほかに階層的クラスタリングやDBSCANなどの手法も活用すると、より深い分析が可能になります。

